9461번: 파도반 수열
문제 오른쪽 그림과 같이 삼각형이 나선 모양으로 놓여져 있다. 첫 삼각형은 정삼각형으로 변의 길이는 1이다. 그 다음에는 다음과 같은 과정으로 정삼각형을 계속 추가한다. 나선에서 가장 긴 �
www.acmicpc.net
<내 코드>
n = int(input())
memo = [0 for _ in range(101)]
for i in range(0, 4):
memo[i] = 1
for j in range(4, 6):
memo[j] = 2
for _ in range(n):
m = int(input())
for k in range(6, m+1): # 6 ~ m-1
memo[k] = memo[k-1] + memo[k-5]
print(memo[m])
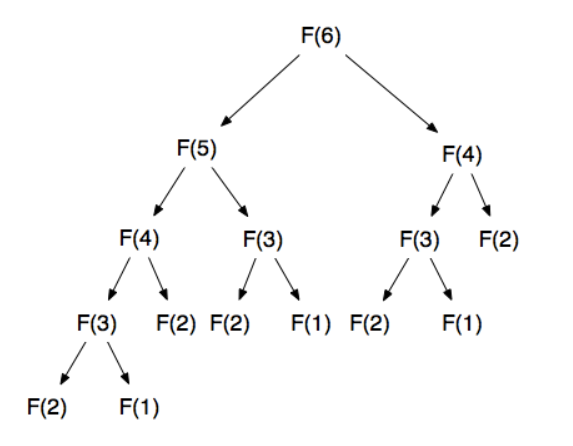
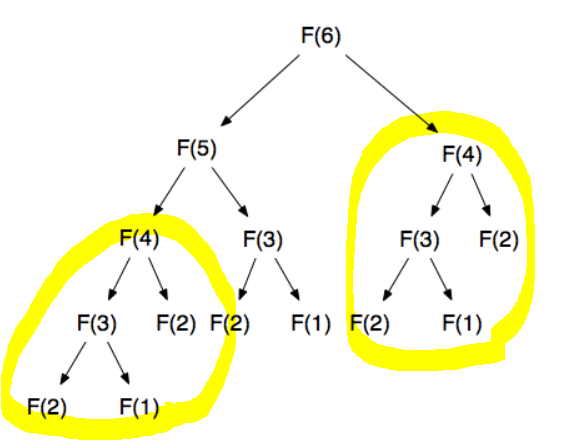
피보나치 수열과 비슷한 맥락으로 규칙을 찾아 점화식을 세우면 간단하게 풀 수 있었다.
인덱스 0번 ~ 4번까지는 1과 2로 넣어주고 그 다음부터는 점화식을 통해 값을 구해나가는 구조였다. 인덱스 값을 0번째 부터 설정해서 뒤에서 조금 헷갈린거 말고는 크게 어렵지 않았다.
반응형
'알고리즘 문제풀기 > 백준 - Python' 카테고리의 다른 글
| [백준 1932] 정수 삼각형 - Python (다이나믹 프로그래밍) (0) | 2020.08.24 |
|---|---|
| [백준 1149] RGB 거리 - Python (다이나믹 프로그래밍) (0) | 2020.08.24 |
| [백준 2748] 피보나치 수 - Python(다이내믹 프로그래밍) (0) | 2020.08.23 |
| [백준 2805] 나무 자르기 - Python(이분탐색) (0) | 2020.08.21 |
| [백준 1920] 수 찾기 - Python (이분탐색) (0) | 2020.08.18 |