배열이나 리스트에서 각 원소에 대해 오른쪽에 있는 원소들 중 자신보다 크거나 같은(또는 보통은 '큰' 경우가 많지만, 변형으로 '크거나 같은' 조건을 쓰기도 한다) 첫 번째 원소를 찾는 문제다.
예시 문제 설명
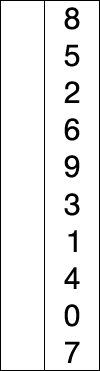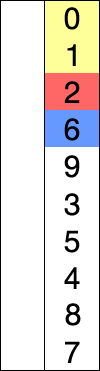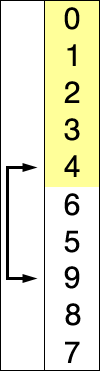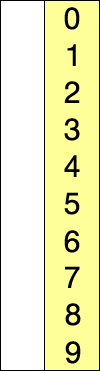
예를 들어, 배열 A가 주어졌을 때A = [3, 5, 2, 7, 5]각 원소에 대해 오른쪽으로 이동하며, 처음 만나는 자신보다 크거나 같은 원소를 찾습니다.
- 3의 오른쪽에는 5, 2, 7, 5가 있는데, 처음으로 3보다 크거나 같은 수는 5입니다.
- 5의 오른쪽에는 2, 7, 5가 있는데, 2는 작으므로 건너뛰고, 다음 7은 5보다 크므로 7이 됩니다.
- 2의 오른쪽에는 7, 5가 있으므로 7이 첫 번째 큰(또는 같은) 수입니다.
- 7의 오른쪽에는 5만 있으나 5는 7보다 작으므로, 7은 오른쪽에 조건을 만족하는 원소가 없는 것으로 처리합니다.
- 마지막 원소인 5는 오른쪽에 아무 원소도 없으므로 조건을 만족하는 원소가 없습니다.
보통 조건을 만족하는 원소가 없을 경우 -1 또는 0 등 특정 값을 반환합니다.
단순하게 이중 반복문을 사용하면, 각 원소마다 오른쪽의 모든 원소를 확인해야 하므로 시간복잡도가 O(n^2)가 된다. 하지만 스택(stack)을 이용하면, 한 번의 순회로 각 원소를 효율적으로 처리할 수 있다.
스택을 사용하는 이유
- 스택의 특징
- 스택은 후입선출(LIFO) 구조다. 이 특성을 이용하면, 배열을 한 번 순회하면서 "아직 답을 찾지 못한 원소들의 인덱스"를 스택에 저장해 두고, 새로운 원소가 들어올 때마다 이전 원소들과 비교하여 조건(큰 혹은 큰/같은)을 만족하는지 빠르게 확인할 수 있다.
- 시간복잡도
- 각 원소는 스택에 한 번 push되고, 조건이 맞으면 pop되므로 각 원소가 스택에 들어가고 나오는 과정이 한 번씩 이루어집니다. 따라서 전체 시간 복잡도는 O(n)이 됩니다.
알고리즘 동작 과정
- 초기화:
빈 스택을 준비하고, 결과를 저장할 배열을 초기화한다. 결과 배열은 각 원소의 "다음 큰(또는 같은) 수"의 인덱스나 값을 저장할 수 있다. - 배열 순회:
배열의 인덱스를 0부터 n-1까지 순회한다.- 현재 원소와 비교:
현재 원소(A[i])가 들어왔을 때, 스택의 최상단에 있는 인덱스(예: j)를 확인한다.- 만약 A[i]가 A[j]보다 크거나(또는 크거나 같은) 하면, A[i]는 A[j]의 조건(다음 큰 또는 같은 수)을 만족하는 원소가 된다.
따라서 결과 배열의 j번째 위치에 A[i] 또는 인덱스 i를 저장하고, 스택에서 j를 pop한다. - 이 과정을 스택이 비거나, 스택의 최상단 원소가 현재 원소보다 크거나 같은 조건을 만족할 때까지 반복한다.
- 만약 A[i]가 A[j]보다 크거나(또는 크거나 같은) 하면, A[i]는 A[j]의 조건(다음 큰 또는 같은 수)을 만족하는 원소가 된다.
- 현재 인덱스 push:
그 후, 현재 인덱스 i를 스택에 push한다.
- 현재 원소와 비교:
- 후처리:
배열 순회가 끝난 후에도 스택에 남아있는 인덱스들은 오른쪽에 조건을 만족하는 원소가 없는 경우다. 이 경우, 결과 배열에 -1 또는 0을 기록한다.
Python 코드 예시
def next_greater_or_equal(arr):
n = len(arr)
result = [-1] * n # 조건을 만족하는 원소가 없으면 -1로 처리
stack = [] # 인덱스를 저장하는 스택
for i in range(n):
# 현재 원소 arr[i]가 스택의 최상단 원소보다 크거나 같으면 조건을 만족
while stack and arr[stack[-1]] <= arr[i]:
idx = stack.pop()
result[idx] = arr[i]
stack.append(i)
return result
# 예시 실행
A = [3, 5, 2, 7, 5]
print(next_greater_or_equal(A)) # 출력 예: [5, 7, 7, -1, -1]
위 글을 요약하자면 다음과 같다.
- 문제: 각 원소에 대해 오른쪽에서 처음으로 자신보다 크거나 같은 원소를 찾는 문제.
- 단순 방법: 이중 반복문을 사용하면 O(n^2) 시간복잡도.
- 스택 사용: 스택을 이용하면 각 원소가 한 번씩만 처리되므로 O(n) 시간복잡도로 해결 가능.
- 핵심: 스택에 아직 답을 찾지 못한 원소의 인덱스를 저장하고, 새 원소가 들어올 때마다 조건에 맞는 이전 원소들을 처리.
반응형
'알고리즘 & 자료구조' 카테고리의 다른 글
| [알고리즘] DFS, BFS (0) | 2024.10.02 |
|---|---|
| [알고리즘] 그리디 알고리즘 (Greedy Algorithm) (0) | 2020.09.05 |
| [알고리즘] 동적 계획법 - Dynamic Programming (0) | 2020.08.23 |
| [알고리즘] 이분 탐색 - Binary Search (0) | 2020.08.18 |
| [알고리즘] 삽입정렬 (0) | 2020.08.17 |